


메시지큐와 이벤트 스트리밍 플랫폼
현대 소프트웨어 아키텍처는 마이크로소프트 방식의 작은 단위들로 구성된다. 그리고 이러한 블록들의 통신을 담당하는 메시지 큐가 존재한다. 대표적으로 아파치 카프카, 아파치 RabbitMA 등이 존재하지만 엄밀히 따지면 아파치 카프카는 이벤트 스트리밍 플랫폼으로 분류된다. 이에 따라 사전에 메시지큐와 이벤트 스트리밍 플랫폼의 차이를 먼저 보면 다음과 같다.
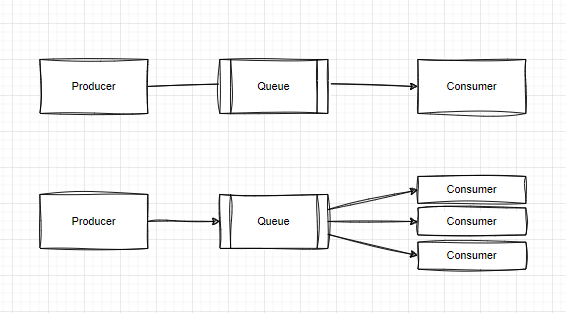
상단에 그린 것이 일반적인 메시지 큐다. 하나의 생산자는 메시지를 큐에 보내고, 이 큐로부터 하나의 소비자가 메시지를 처리한다.
이와 달리 하단의 이벤트 스트리밍 플랫폼은 하나의 생산자가 메시지를 큐에 보낼 때 다수의 소비자가 각자의 시점에서 데이터를 처리할 수 있다.
메시지큐에 대한 고려사항
메시지 큐를 적용할 때 할 수 있는 고려사항은 아래와 같다.
- 메시지의 형태(Text, 멀티미디어 등)와 평균 크기(kb)가 어떻게 되는가?
- 메시지는 여러 소비자에게 반복 전달 되어야 하는가?
- 메시지의 소비 순서는 생성 순이어야 하는가?
- 메시지의 보관정책이 존재하는가?
- 메시지의 전달 횟수 정책이 있는가? (최소 수, 최대 수, 절대 수 등)
메시지 모델 고려하기
일대일 메시지 모델
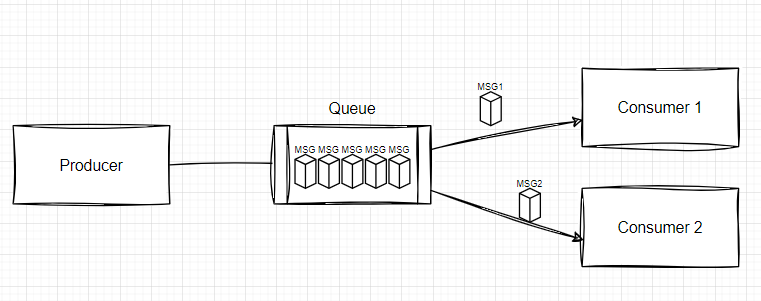
일대일 모델에서는 큐에 전송된 메시지는 오직 한 소비자만 가져갈 수 있다. 이는 곧 한 사람이 가져가면 보관할 이유도 없으니 한 번 소비되면 그대로 사라지는 것이다. 그렇다면 앞의 고려사항 중에, 여러 소비자에게 반복 전달될 필요가 없고 보관정책도 별도의 요구가 없다면 고려해볼 수 있게 되겠다.
우선 기억할 것은 소비자 단위에 따라 큐의 메시지가 소비된다는 것이다
발행 구독 메시지 모델
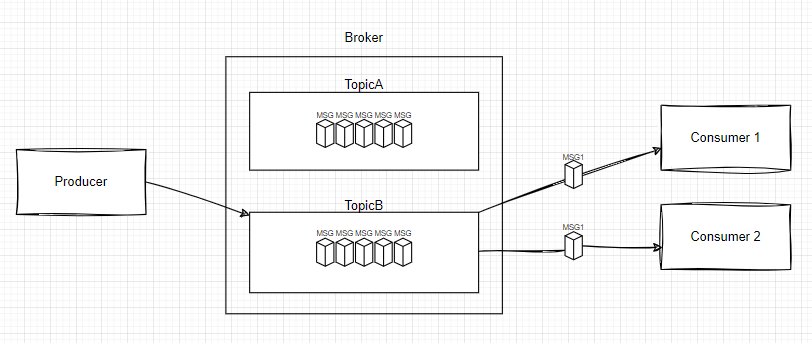
Topic이라는 개념이 도입되는 메시지 모델이다. 큐에 전송된 특정 Topic 연관 메시지는 특정 Topic을 구독하고 있는 사용자 모두에게 전송한다. 이처럼 일대일 모델과는 대비되는 토픽 단위에 따라 메시지가 소비되고 있다
발행 구독 메시지 모델 상세히 파해치기
이전에 보았을 때, message는 Topic에 보관된다. 그러다 데이터 양이 증가되어 서버 한 대로 감당하기 힘들다면 분산시킬 때다.
이를 위한 방법이 파티션(partition), 즉 샤딩(sharding)이다.
파티션

복제 된 상태는 아니다. 전체를 각 파티션이 그 이름처럼 분배하여 갖고 있다. 그렇게 분배되어 같은 파티션 안에 있는 Msg들은 순서가 유지되어있다. 이 파티션에 분배되는 기준은 직접 정할 수도 있고(key를 통해), 무작위로 전달(key가 없다면)될 수도 있다.
그렇다면 이제 이렇게 나누어진 파티션을 소비자들이 데이터를 가져올 수 있다. 이때 각 소비자들은 파티션을 하나 이상 이용할 수 있다. 더불어, 소비자들은 단일이라고 단정짓지 않아도 된다. 소비자들은 소비자 그룹으로, 여러개의 모임으로 확장시킬 수 있다
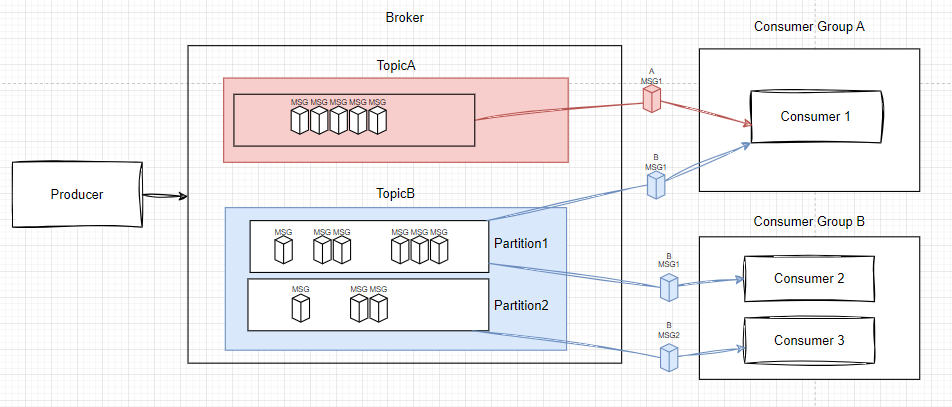
예로 그린 그림을 예로 들어 설명하자면 다음과 같다
- 하나의 Topic 내의 메시지는 여러 Partition으로 나뉠 수 있다
- 각 Partition은 전체 메시지를 분산시켜 갖고있는 상태다 (복제된 게 아니다)
- ConsumerGroup은 여러 소비자로 구성될 수 있다
- ConsumerGroup은 여러 Topic의 각 partition을 구독할 수 있다
- ConsumerGorup 각각은 offset을 달리 갖고 있다(A그룹이 10까지 소비했더래도, B그룹은 3부터 소비할 수 있다)
위와 같은 상황을 인지했다면, 이제 한 가지 문제를 떠올릴 수 있다.
TopicB에 대한 메시지 보장은 어떻게 하지?
그림에서 ConsumerGroup B의 경우, 각각의 내부 소비자가 서로 다른 파티션으로 분배된 메시지를 읽는 순서는 최초의 메시지 생성 순서와 동일하지 않을 수 있다는 점이다. 즉 병렬소비가 일어나면서 순서가 보장되지 않게되었단 말이다.
그렇다면 이제 Topic의 partition을 하나로 두는 것을 고안할 수 있다
파티션: 한 Topic에 대하여 하나의 partition을 둠으로써 순서 보장하기
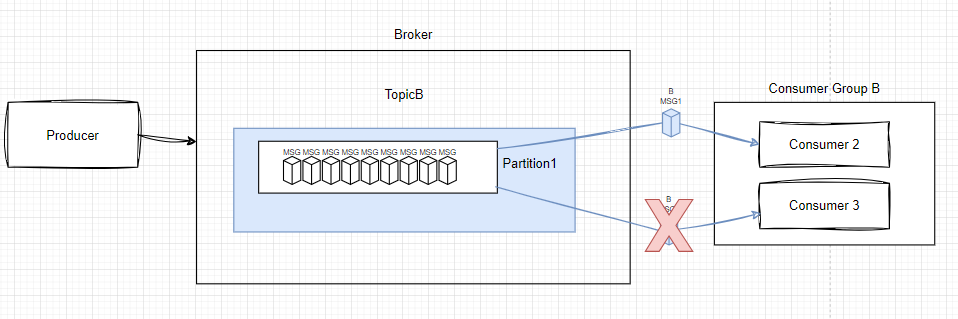
Topic의 순서보장을 위하여 Partition을 하나로 사용할 것을 정했다면, 주의해야할 점이 있다.
그룹 내 소비자의 수가 구독하는 토픽의 파티션 수보다 크다면 그 큰 개수만큼 Consumer는 해당 Topic에 대해 수신받지 못한다. 따라서 불필요한 내부 컨슈머를 계속 보유할 필요가 없다. 더불어 이렇게 되면 일대일 모델에 가까워짐을 상기하자.
물론 Consumer의 처리량 자체를 높이고자 한다면, Consumer Group을 추가하는 방법은 있다. 특히나 나의 경우, 각각의 Consumer들은 message를 전송해야할 상대방을 나누어서 알고 있다. 따라서 Partition 내 같은 메시지를 각 ConsumerGroup이 읽고 서로가 다르게 알고있는 사용자에게 전송하도록 분산시켰다.
파티션: 한 Topic에 대하여 여러 partition을 두면서 순서를 보장하기
한 Topic 내에 카테고리같은 개념이 존재한다면, 그리고 그 카테고리 내에서만 순서를 보장해도 된다라는 가정이 있다면 Key를 고정시킴으로써 적어도 한 서버는 key를 기준으로 순서를 보장시키게 할 수 있다
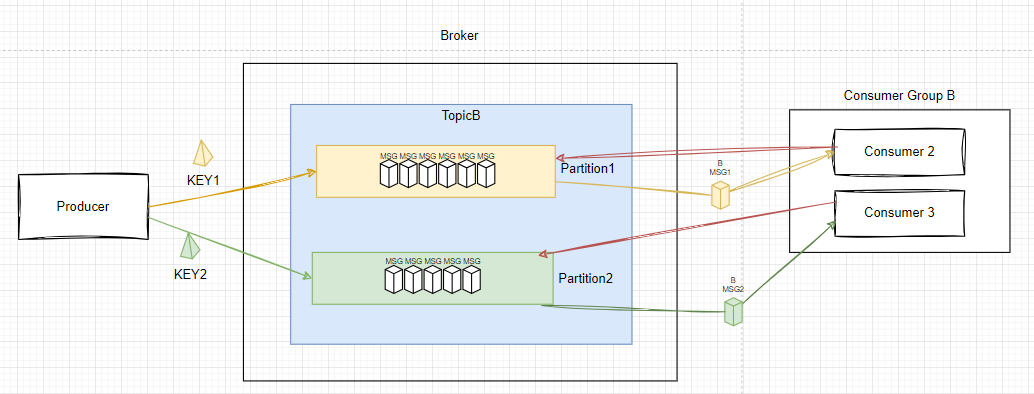
과정은 아래와 같다.
1. 빨간색과 같이 최초에 Consumer은 특정 partition을 할당받은 상태다
2. 노랑, 초록과 같이 Producer는 메시지 발생 시 key를 지정하여, 해당 Key로만 갈 수 있는 유일한 partition을 지정한다
ex) 특정 유저별로 순서대로 발생시키고 싶다면 이 키는 UserId를 활용할 것이다
3. 할당 받은 partition에 따라 각 내부 소비자가 할당받으며 순서대로 처리할 수 있게 된다
전체적인 메시지 큐 구조를 보았다.
다음은 이러한 사항을 배경으로 Producer와 Consumer의 작업을 더욱 상세히 볼 차례다.
Reference
Kafka 메시지 순서 보장 확인해보기
모든 소스 코드는 https://github.com/lkimilhol/kotlin-kafka-toy 에서 확인 가능합니다. 오늘의 고민 내용은 카프카를 통하여 메시지를 순서대로 받을 수 있을까 입니다. 사실 이는 가능한데요. 카프카의 파
kimmayer.tistory.com
Kafka에서 partition 수와 메시지 순서
메시지를 순서대로 consume하는 것이 보장됨.topic에 대해 모든 데이터의 순서를 보장받고 싶다면, topic 생성 시 partition의 수를 1로 지정해야 함.consumer는 1 3 2 순으로 메시지를 가져왔음.consumer는 각
velog.io
Kafka Partition key를 사용하여 데이터 순서대로 처리하기
Kafka에서 하나의 Topic은 여러 Partition으로 파티셔닝 될 수 있다. 하나의 Partition은 동일한 Consumer Group 내에서 하나의 Consumer에 의해 처리되기 때문에, Partition의 개수를 늘려 Consumer Group에 대해 하나
devs0n.tistory.com
가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 | 알렉스 쉬 - 교보문고
가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 | 구글 맵, 지메일, 아마존 S3 같은 대규모 시스템은 어떻게 설계할까? 글로벌 기업 시스템 설계에 몸담은 핵심 인물들의 노하우를 집대성했
product.kyobobook.co.kr