

마이크로서비스 아키텍처라든지 분산 시스템을 설계하다보면 특정 서비스로의 요청 폭주를 방지하거나 공정한 자원 분배를 위해 얼만큼 트래픽을 관리할 것인지에 대한 처리율 제한 알고리즘도 설계해 반영할 일이 있다.
쉽게 말해 "너무 많이 요청하지 말라"고 하기 위한 신호등 느낌이다. 한 번에 너무 많은 요청(클릭, 데이터 요청)이 들어온다면 시스템은 멈추거나 느려지는 현상이 나타날테니, 이를 위해 "몇 개까지만 허용할게" 라고 정해 그 이상은 거절한다든지, 멈추겠다든지 등을 결정해볼만 하다.
물론 과부화 요청에 대한 시스템의 처리속도의 향상과 더불어, 다수의 사용자 중 일부 사용자만 독점하지 않게하며 보안적으로도 안전성을 갖추기 위해 적용시킬 수 있다.
대표적인 처리율 제한 알고리즘 - 토큰 버킷 알고리즘을 알아보면 아래와 같다.
토큰 버킷 알고리즘

우선, '토큰(Token)'이라고 하면 요청을 처리할 수 있는 권한 나타내는 개념이다. 그래서 이 알고리즘에서는 '정해진 속도'로 토큰을 버킷(Bucket)에다가 채우고, 요청이 들어올 때마다 토큰을 꺼내쓴다. 마치 자판기처럼 토큰을 넣고 요청을 처리하길 기다린다.
동작과정
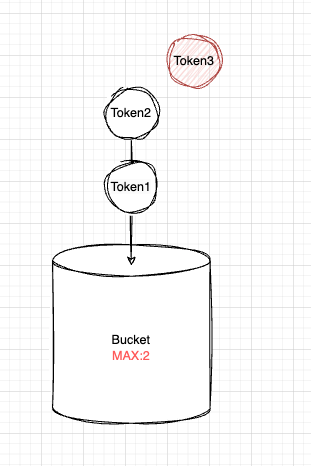
1초 마다 토큰이 생기고 있다. 그리고 버킷은 토큰을 담아두는 통으로써 1초마다 생기는 토큰을 받아주고 있다. 이 버킷은 최대크기(최대 토큰 수)가 정해져 있어서 그린 것과 같이 해당 MAX 값을 넘어선다면 새로 생성되었던 토큰은 버려질 예정이다.
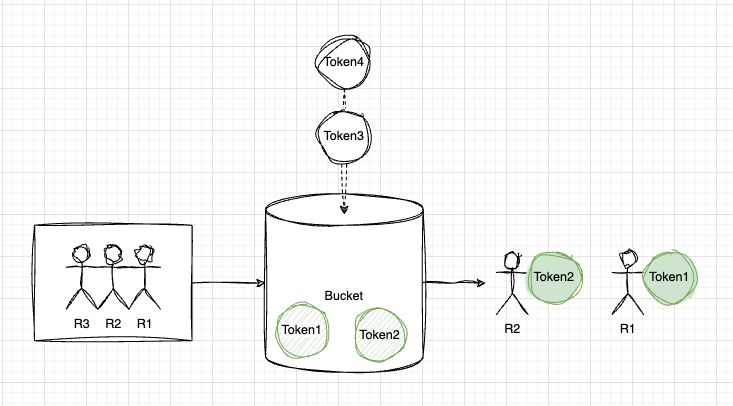
이제 그린 것처럼 충분한 Token양을 Bucket이 갖고 있다.
그러면 이제 요청(Request)이 들어올 때마다 Bucket이는 Token을 소진시키기 시작한다. 만약에 해당 토큰이 Bucket에 충분치 않다면 요청 자체가 거부되거나 대기될 예정이다.
특징
한 번에 요청이 몰려도 토큰만 있다면 바로 처리할 수 있고, 토큰의 생성속도에 따라 요청 처리 속도도 함께 제어되는 쉬운 방식이다. 다만, 그 속도를 어떻게 '적절하게' 유추해내서 설정할 지가 어려운 거다. 만약 짧은 순간 이벤트성으로 폭발하듯 발생한 트래픽을 처리해내야하는데 평균적인 속도로만 받아낸다면 문제다.
사용 예제
여기서 버킷을 몇 개를 두냐는 이제 서비스의 성격에 따라 달라진다.
앞서 봤듯이 버킷은 처리할 수 있는 Max가 정해져있고, 토큰을 생성하는 속도도 정해져있다. 그러니, '모든 사용자가 같은 속도로 제한되길 원해.' 라는 상황이라면 하나의 버킷만 있어도 된다.
하지만 사용자별로 요청을 제한할 거라면? 로그인 요청은 초당 5개 허용하고 싶고 조회 요청은 초당 50개만 허용하고 싶다면? 지역별로, 미국 서버는 100개 유럽 서버는 50개만 허용하고 싶다면? 고객의 등급별로 제한을 걸고 싶다면?
이러한 공급 제한 규칙의 범위별로 버킷은 여러 개 생성하게 된다.
아래는 토큰 버킷 객체를 Java로 만든 경우다
import java.util.concurrent.atomic.AtomicInteger;
public class TokenBucket {
private final int capacity;
private final int refillRate;
private AtomicInteger tokens;
private long lastRefillTimestamp;
public TokenBucket(int capacity, int refillRate) {
this.capacity = capacity;
this.refillRate = refillRate;
this.tokens = new AtomicInteger(capacity);
this.lastRefillTimestamp = System.currentTimeMillis();
}
public synchronized boolean tryConsume() {
refill(); // 토큰 채우기
if (tokens.get() > 0) {
tokens.decrementAndGet(); // 토큰 사용
return true; // 요청 처리 가능
} else {
return false; // 토큰 부족
}
}
// 버킷에 토큰을 채우는 메서드
private void refill() {
long now = System.currentTimeMillis();
long elapsedTime = now - lastRefillTimestamp;
int newTokens = (int) (elapsedTime / 1000 * refillRate); // 초당 생성된 토큰 수 계산
if (newTokens > 0) {
tokens.set(Math.min(capacity, tokens.get() + newTokens)); // 최대 토큰 개수를 넘지 않게
lastRefillTimestamp = now;
}
}
}
선언된 필드
private final int capacity;
private final int refillRate;
private AtomicInteger tokens;
private long lastRefillTimestamp;- capacity: 버킷에서 담을 수 있는 최대 토큰 수다. 10이면 10까지만.
- refilRate: 초당 생성할 토큰 수다. 2라면 초당 2개를 생성할 것이다
- tokens: 잔여 토큰량이다 (이때, AtomicInteger를 통해 멀티스레드 환경의 동시성 문제를 방지한다)
- lastRefillTimestamp: 마지막으로 토큰을 채운 시간인데, 이를 기록함으로써 새 토큰을 추가할 기준점을 만든다
요청에 대한 토큰을 취하는 메소드
public synchronized boolean tryConsume() {
refill(); // 토큰 채우기
if (tokens.get() > 0) {
tokens.decrementAndGet(); // 토큰 사용
return true; // 요청 처리 가능
} else {
return false; // 토큰 부족
}
}
private void refill() {
long now = System.currentTimeMillis();
long elapsedTime = now - lastRefillTimestamp;
int newTokens = (int) (elapsedTime / 1000 * refillRate); // 초당 생성된 토큰 수 계산
if (newTokens > 0) {
tokens.set(Math.min(capacity, tokens.get() + newTokens)); // 최대 토큰 개수를 넘지 않게
lastRefillTimestamp = now;
}
}
tryConsume()은 요청이 들어왔을 때 잔여 토큰량에 따라 토큰을 가져간다. 이때, 여기서도 스레드의 동시 접근에 대한 문제를 해결하고자 동기 메소드(synchronized 키워드)로 만들어두었다. 가령 refil() 함수에서 동기화 없이 두 스레드가 진행되게 만들어버린다면 동일한 lastRefillTimestamp에 대한 잘못된 업데이트를 할 수 있고, tokens.get() 호출 시점에는 각자가 독립적으로 1이라고 생각하여 decrement()를 진행하고 보니 -1까지 가버리는 경우가 있을 수 있다.
그렇다면 AtomicInteger는 왜 썼냐는 궁금증이 있을 수 있는데, AtomicInteger 자체는 tokens 필드의 증가 및 감소 연산을 안전하게 하는 역할을 한다. 사실상 추후에 tokens에 대한 증가/감소 로직이 확장될 것을 생각하여 넣긴 했으나, 해당 메소드에서는 int와 ++, -- 등을 사용해도 무관하리라 예상한다.
그리고 tryConsume()에서 refil()을 호출하는 모양을 보면 알 수 있듯이, 실제로 1초마다 token이 생성된다라는 로직이 아니다. 그러한 불필요한 동작을 하는 것보다, 요청이 들어온 시점을 기준으로 해당 시점이 토큰이 얼만큼 생성될 것이었는지, 그럼 지금 실제로 최신화된 토큰량이 얼만큼인이 요청 시점의 갱신을 이룬다.
다음은 누출 버킷 알고리즘을 데려와보자 ㅎㅎ