

인덱스
저번에 말한 바와 동일하게 이런 특징이 있다
- B-Tree 등의 자료구조 기반의 효율적인 탐색이 가능하다
- 특정 열(Column)에 대해 정렬된 형태로 저장하여 검색 속도를 높인다
- 데이터가 많아질수록 index의 유무가 쿼리 성능에 큰 영향을 미친다
그리고 이제 이 인덱스는 그 특징에 따라 분류할 수 있다.
클러스터/비클러스터(Cluster/NonCluster) 인덱스
잘 알려진 지식으로 테이블의 PK는 보통 인덱스 설정이 되어있음을 우린 알고 있다. 이와 관련하여 클러스터/비클러스터 유형이 있는데, 이 PK가 '클러스터 인덱스' 유형에 속한다.
✔️ 클러스터 인덱스
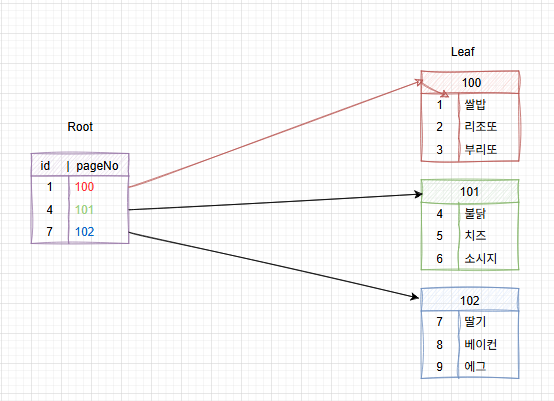
간단히 그렸다. 그림을 보면
- 인덱스 페이지 내에서 Root 노드는 PK(id)를 Key로, Page에 위치에 대한 포인터를 갖고 있다.
- 인덱스 페이지 내 연결된 Leaf 노드를 찾아가면 PK(id)를 Key로, 실제 데이터를 담고 있다. (PostgreSQL의 경우 Leaf 노드에 데이터가 저장되는 건 아니다)
더불어 Leaf 노드와 Root 노드 둘다 PK(id)를 기준의 내부 순차 정렬 상태를 갖고있다.
종합하면 클러스터형 인덱스는 해당 값을 기준으로 데이터가 물리적으로 정렬된 상태를 결정한다.
✔️ 비클러스터 인덱스
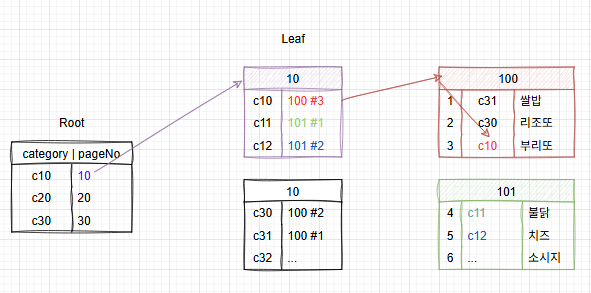
비클러스터의 경우
1. Root 노드에서 인덱스가 설정된 Column(category)에 대하여 탐색을 시작한다.
2. 단계에 따라 Branch 노드를 지난 후, Leaf 노드에서 테이블 데이터 위치(페이지 번호, 행 번호)를 찾는다
3. 최종적으로 테이블에 있는 물리적 데이터를 얻어낸다
단, 여기서 이제 실제 물리적 데이터의 정렬상태는 category에 영향을 받지 않은 상태이다.
더불어 DBMS에 따라서 Leaf 노드에 PK값을 가질 수도, TID를 가질 수도 있다
DBMS에 따라 과정이 다르긴 하지만, 결국에 주요요점은 클러스터 인덱스라면 일반적으로 실제 데이터의 정렬에 영향을 끼치게 된다는 것이다. (하나만 짚고가자면 postgreSQL의 경우 PK라고 할지라도 직접 정렬에 영향을 가하지 않는 비클러스터형 인덱스로 존재한다.)
대부분의 DBMS에 존재하는 클러스터형 인덱스를 잘 사용하려면 무작위 값을 갖는 UUID는 기본키로 쓰는 것을 지양해야 한다. 이 무작위한 UUID를 통해 Heap 구성을 시키려면 굉장히 비효율적이게 되어버린다.
가령 데이터 삽입 시, 테이블의 정렬을 위해선 순차적으로 확인하는 게 아니라 매번 무작위 값을 위한 탐색비용이 들어간다. 중간에 끼어드는 방식으로 인해 기존의 페이지 공간이 어긋나고 이것이 페이지 분할로 이어지며 데이터의 이동 작업도 일어난다. 또한 임시 저장 용도였던 캐시도 형태가 달라지므로 더욱 효율이 나빠진다.
Explain 도구를 통한 성능 확인 (PostgreSQL)
이제 인덱스가 얼마나 성능에 미치는가를 자세히 보기 위해 explain 명령어를 사용한다. 그러면 index의 사용 여부를 포함한 쿼리 실행 계획을 확인할 수 있다
✔️ 테스트 데이터 가져오기
적어도 몇만 건이 존재하는 상황을 가정하고자 공공기관 데이터 포탈에서 식품 영양성분에 대한 csv를 가져온다
전국통합식품영양성분정보(음식)표준데이터
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
csv 파일을 가져다 테이블로 넣으면 아래처럼 넣어질 텐데, 한글 column은 맘에 들지 않으므로 영문 교체를 시켰다.
ALTER TABLE ingredient RENAME COLUMN "식품코드" TO code;
ALTER TABLE ingredient RENAME COLUMN "식품명" TO name;
ALTER TABLE ingredient RENAME COLUMN "데이터구분코드" TO data_category_code;
ALTER TABLE ingredient RENAME COLUMN "데이터구분명" TO data_category_name;
ALTER TABLE ingredient RENAME COLUMN "식품기원코드" TO food_origin_code;
ALTER TABLE ingredient RENAME COLUMN "식품기원명" TO food_origin_name;
ALTER TABLE ingredient RENAME COLUMN "식품대분류코드" TO food_major_category_code;
ALTER TABLE ingredient RENAME COLUMN "식품대분류명" TO food_major_category_name;
ALTER TABLE ingredient RENAME COLUMN "대표식품코드" TO main_food_code;
ALTER TABLE ingredient RENAME COLUMN "대표식품명" TO main_food_name;
ALTER TABLE ingredient RENAME COLUMN "식품중분류코드" TO food_middle_category_code;
ALTER TABLE ingredient RENAME COLUMN "식품중분류명" TO food_middle_category_name;
ALTER TABLE ingredient RENAME COLUMN "식품소분류코드" TO food_sub_category_code;
ALTER TABLE ingredient RENAME COLUMN "식품소분류명" TO food_sub_category_name;
ALTER TABLE ingredient RENAME COLUMN "식품세분류코드" TO food_detail_category_code;
ALTER TABLE ingredient RENAME COLUMN "식품세분류명" TO food_detail_category_name;
ALTER TABLE ingredient RENAME COLUMN "영양성분함량기준량" TO nutrition_reference_amount;
ALTER TABLE ingredient RENAME COLUMN "에너지(kcal)" TO energy_kcal;
ALTER TABLE ingredient RENAME COLUMN "수분(g)" TO moisture_g;
ALTER TABLE ingredient RENAME COLUMN "단백질(g)" TO protein_g;
ALTER TABLE ingredient RENAME COLUMN "지방(g)" TO fat_g;
ALTER TABLE ingredient RENAME COLUMN "회분(g)" TO ash_g;
ALTER TABLE ingredient RENAME COLUMN "탄수화물(g)" TO carbohydrate_g;
ALTER TABLE ingredient RENAME COLUMN "당류(g)" TO sugar_g;
ALTER TABLE ingredient RENAME COLUMN "식이섬유(g)" TO dietary_fiber_g;
ALTER TABLE ingredient RENAME COLUMN "칼슘(mg)" TO calcium_mg;
ALTER TABLE ingredient RENAME COLUMN "철(mg)" TO iron_mg;
ALTER TABLE ingredient RENAME COLUMN "인(mg)" TO phosphorus_mg;
ALTER TABLE ingredient RENAME COLUMN "칼륨(mg)" TO potassium_mg;
ALTER TABLE ingredient RENAME COLUMN "나트륨(mg)" TO sodium_mg;
ALTER TABLE ingredient RENAME COLUMN "비타민 A(μg RAE)" TO vitamin_a_rae_μg;
ALTER TABLE ingredient RENAME COLUMN "레티놀(μg)" TO retinol_μg;
ALTER TABLE ingredient RENAME COLUMN "베타카로틴(μg)" TO beta_carotene_μg;
ALTER TABLE ingredient RENAME COLUMN "티아민(mg)" TO thiamine_mg;
ALTER TABLE ingredient RENAME COLUMN "리보플라빈(mg)" TO riboflavin_mg;
ALTER TABLE ingredient RENAME COLUMN "니아신(mg)" TO niacin_mg;
ALTER TABLE ingredient RENAME COLUMN "비타민 C(mg)" TO vitamin_c_mg;
ALTER TABLE ingredient RENAME COLUMN "비타민 D(μg)" TO vitamin_d_μg;
ALTER TABLE ingredient RENAME COLUMN "콜레스테롤(mg)" TO cholesterol_mg;
ALTER TABLE ingredient RENAME COLUMN "포화지방산(g)" TO saturated_fatty_acid_g;
ALTER TABLE ingredient RENAME COLUMN "트랜스지방산(g)" TO trans_fatty_acid_g;
ALTER TABLE ingredient RENAME COLUMN "출처코드" TO source_code;
ALTER TABLE ingredient RENAME COLUMN "출처명" TO source_name;
ALTER TABLE ingredient RENAME COLUMN "1회 섭취참고량" TO single_serving_reference;
ALTER TABLE ingredient RENAME COLUMN "식품중량" TO food_weight;
ALTER TABLE ingredient RENAME COLUMN "품목제조보고번호" TO item_manufacture_report_no;
ALTER TABLE ingredient RENAME COLUMN "제조사명" TO manufacturer_name;
ALTER TABLE ingredient RENAME COLUMN "수입업체명" TO importer_name;
ALTER TABLE ingredient RENAME COLUMN "유통업체명" TO distributor_name;
ALTER TABLE ingredient RENAME COLUMN "수입여부" TO is_imported;
ALTER TABLE ingredient RENAME COLUMN "원산지국코드" TO origin_country_code;
ALTER TABLE ingredient RENAME COLUMN "원산지국명" TO origin_country_name;
ALTER TABLE ingredient RENAME COLUMN "데이터생성방법코드" TO data_creation_method_code;
ALTER TABLE ingredient RENAME COLUMN "데이터생성방법명" TO data_creation_method_name;
ALTER TABLE ingredient RENAME COLUMN "데이터생성일자" TO data_creation_date;
ALTER TABLE ingredient RENAME COLUMN "데이터기준일자" TO data_reference_date;
ALTER TABLE ingredient RENAME COLUMN "제공기관코드" TO providing_agency_code;
ALTER TABLE ingredient RENAME COLUMN "제공기관명" TO providing_agency_name;
기존에 없던 id 컬럼을 생성시켜 1, 2, 3 ... 으로 채번시켰다.
✔️ 쿼리 실행 계획 확인하기
explain analyze select id, name from ingredient where id > 0;
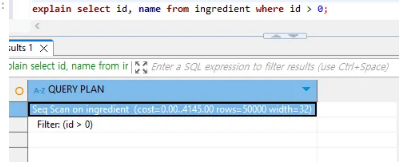
이제 explain 명령어 수행 시 5만 개 로우에 대한 쿼리 실행 계획을 살펴볼 수 있다.
✔️ 특정 ID를 갖는 데이터 조회
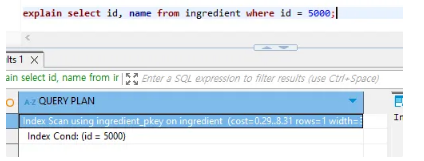
일반적으로 예상한 바와 같이 where절에 PK값을 검색한다면 index를 타고 page를 통해 데이터를 찾는 작업이 진행될 거다. 그 내용이 Query Plan에 있는 index Cond로 수행되고 있음을 유추할 수 있다.
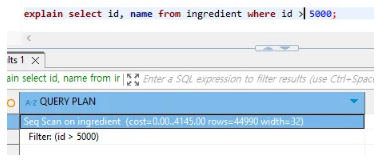
조건을 달리하여 5만개의 데이터 중 id가 5000이상인 것만 조회했다. 이전과 달리 'index Cond'가 나타나지 않았다.
너무 많은 데이터를 출력해야 하는 상황에선 postgre가 인덱스를 통한 검색을 포기하고 순차 검색으로 선택지를 돌린 상황이다.
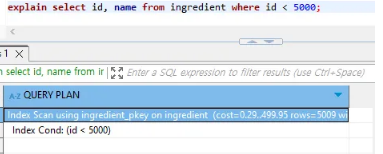
반대로 5000 이하인 ID를 검색하면 상대적으로 적은 양의 데이터를 찾아내면 되므로 index를 통해 검색하고 있음을 볼 수 있다.
알 수 있는 것은 우리가 인덱스를 설정했다한들 100%의 사용을 확신할 수 없다. 내부 동작에 따라 그 인덱스의 실제 사용 여부가 결정된다. (행이 많아? 순차탐색 할래. 행이 적어? 인덱스 쓸게)
Like 연산에 대한 explain
create index index_name on ingredient(name);
이번엔 text 속성을 가진 name에 대하여 index 설정을 했다고 해보자. 이후 like 연산을 통해 조회를 하면 이 또한 인덱스가 사용되지 않는다. 와일드카드(%)가 앞에 와버리니까 순차적으로 검색할 방법을 찾지 못하고 풀 스캔을 하고 있는 것이다.
따라서 순차 검색을 통해 필터 결과 제외되는 것은 삭제하는 동작을 볼 수 있다. (%를 지양하는 것도 방법인데, pgtrgm 확장을 사용하는 방법도 있다)
Bitmap Index Scan
일반적인 Index Scan과 달리 여러 조건을 동시에 만족하는 데이터를 효율적으로 찾기 위해 존재하는 Bitmap Index가 있다. 조건이 많거나 데이터가 클 때 유리하다. 얘는 아래의 단계를 따른다.
1. 각 조건에 대한 비트맵을 생선한다
2. 비트맵을 병합한다
3. 필요한 페이지만 접근한다
예시를 들어보자
explain select name from ingredient where id > 30000 and sugar_g > 50;
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
테이블에 대해 두 개의 인덱스에 대해서 조회 조건을 걸었다. 그리고 기본적인 비트맵 표가 있다.
이 비트맵은 힙 테이블에 있는 페이지의 개수만큼 존재하고, 해당 페이지에 조건이 만족하는 지를 표기할 수 있다.
1. 각 조건에 대한 비트맵 생성
id에 대한 Bitmap Scan (예시임)
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
sugar_g에 대한 Bitmap Scan ( 예시임)
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
2. id와 sugar_g에 대한 비트맵 병합 ( id & sugar_g)
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
두 개를 &연산을 함으로써 공통된 페이지만 조회하게 된다.
3. 필요한 페이지만 접근하여 데이터 가져오기
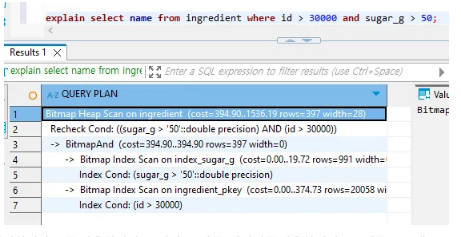
explain 결과를 통해 알 수 있듯이, 실제로 Bitmap을 통해 연산이 수행되었고 각각의 조건을 병합하여 예측컨데 397개의 데이터가 최종적으로 출력될 수 있음을 볼 수 있다.
다음은 이제 Index Only, 인덱스 결합을 알아야하는데...